QualiVision: Multi-Modal Video Quality Assessment with Quality-Aware Fusion and Discriminative Learning Strategies
Abstract
The proliferation of AI-generated video content across media production, entertainment, and social platforms has created new challenges in automatic quality assessment. While traditional metrics focus primarily on technical artifacts, AI-generated content requires comprehensive evaluation across temporal consistency, image fidelity, aesthetic appeal, and text-video alignment to ensure semantic coherence between input prompts and visual outputs. We present QualiVision, a multi-modal video quality assessment framework designed to address these requirements. Working with the VQualA 2025 challenge dataset of 4,000 annotated AI-generated videos, we develop two complementary architectures that integrate video understanding with textual prompt analysis. Our first approach enhances DOVER++ with a quality-aware cross-modal fusion mechanism that dynamically adapts attention based on textual content. The second employs V-JEPA2 with strategic layer freezing and discriminative learning rates for efficient adaptation of large-scale transformers. Both models utilize a hybrid loss function combining smooth L1, ranking, and scale-aware components to better align with human perceptual judgments. Experimental evaluation of our V-JEPA2 architecture achieved a final score of 0.57, and DOVER++ obtained 0.39 on the challenge test set, demonstrating the effectiveness of cross-modal understanding for AI-generated video quality assessment.
Methodology
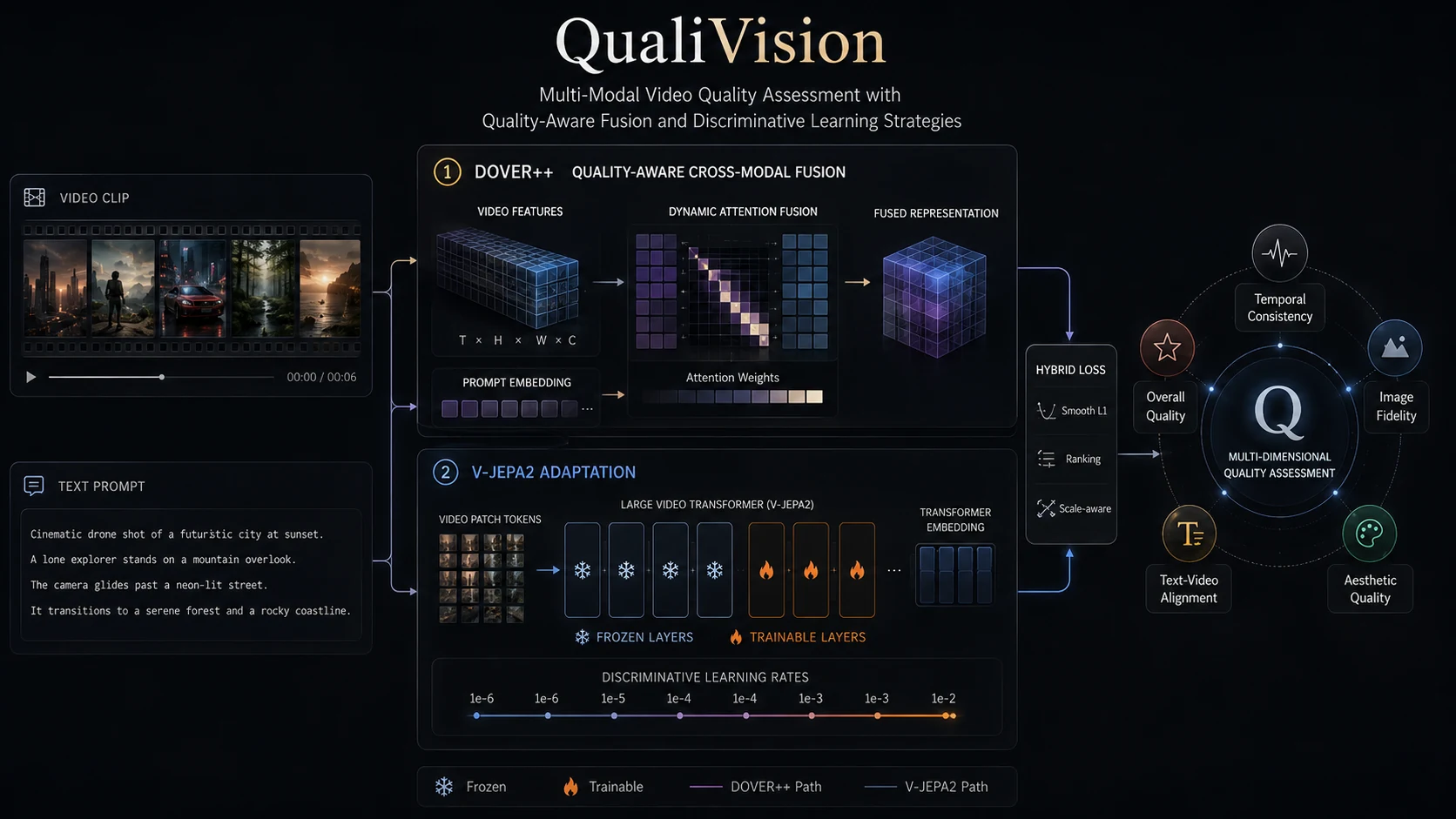
QualiVision evaluates AI-generated videos across temporal consistency, image fidelity, aesthetic appeal, text-video alignment, and overall quality. The paper proposes two complementary multimodal architectures. The first extends DOVER++ with quality-aware cross-modal fusion, where text embeddings guide attention over video quality dimensions. The second adapts V-JEPA2 using strategic layer freezing and discriminative learning rates, allowing a large video transformer to be fine-tuned efficiently for quality assessment. Both approaches use a hybrid loss combining smooth L1 loss, ranking loss, and scale-aware loss to better align model predictions with human perceptual scores.
Results
| Method | Validation Score | Test Score |
|---|---|---|
| DOVER++ | 0.52 | 0.39 |
| V-JEPA2 | 0.63 | 0.57 |
V-JEPA2 reaches 0.57 on the official VQualA challenge test set, with DOVER++ at 0.39. Ablations in the paper attribute the largest gains to cross-modal fusion (DOVER++) and strategic layer freezing (V-JEPA2).
Citation
@InProceedings{Bompilwar_2025_ICCV,
author = {Bompilwar, Ritik and Koshatwar, Saurabh},
title = {QualiVision: Multi-Modal Video Quality Assessment with Quality-Aware Fusion and Discriminative Learning Strategies},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops},
month = {October},
year = {2025},
pages = {3469-3478}
}